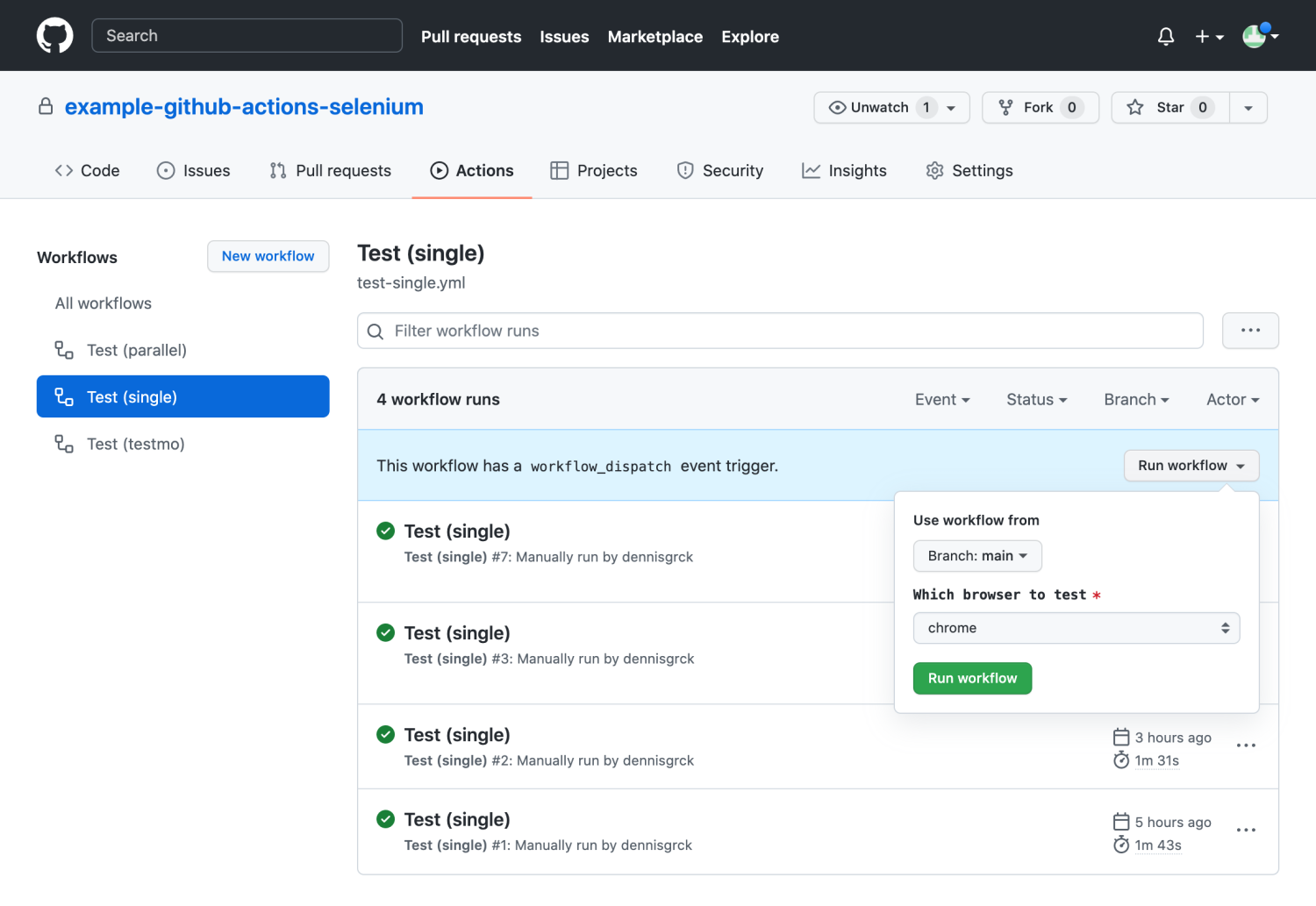
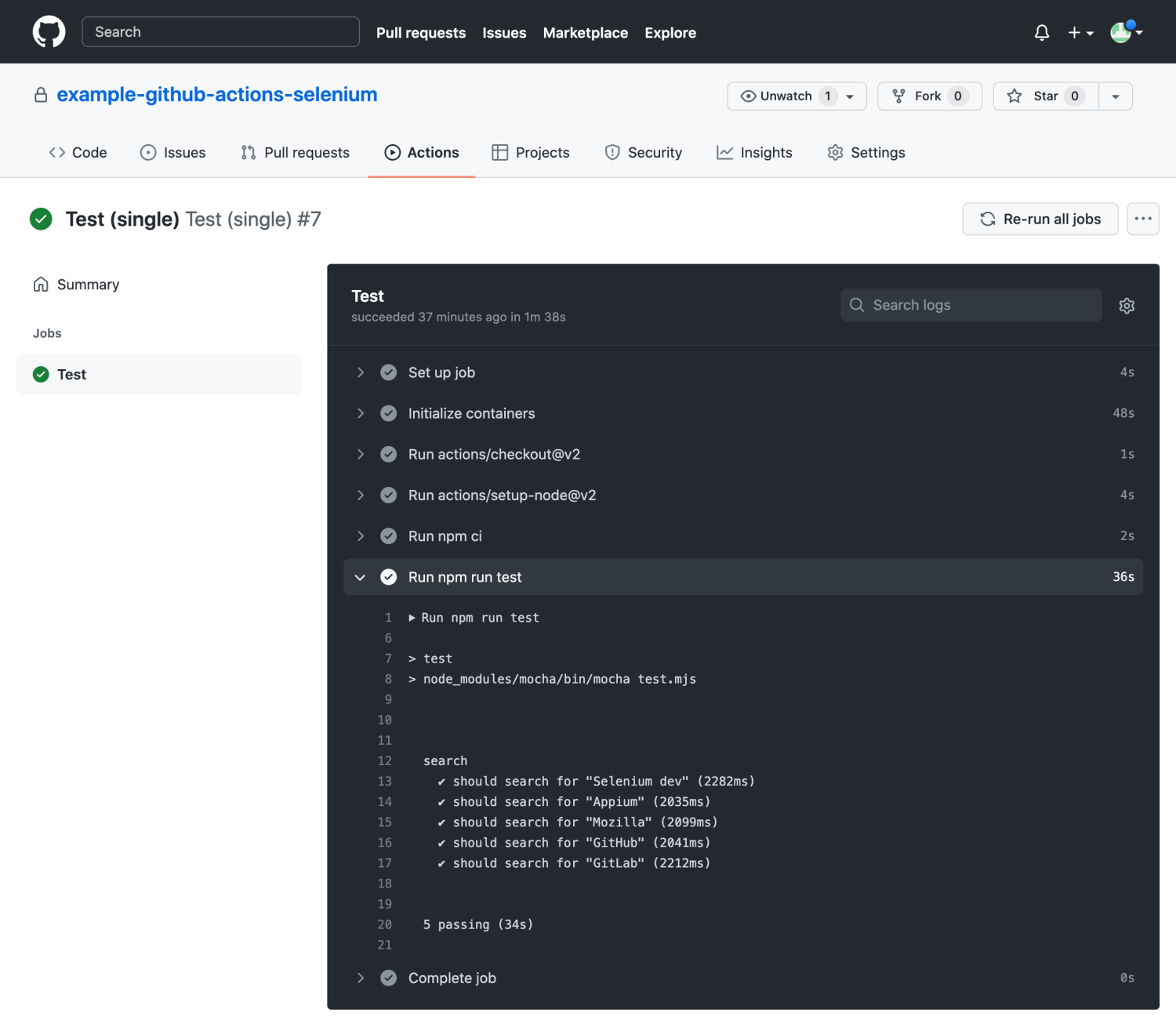
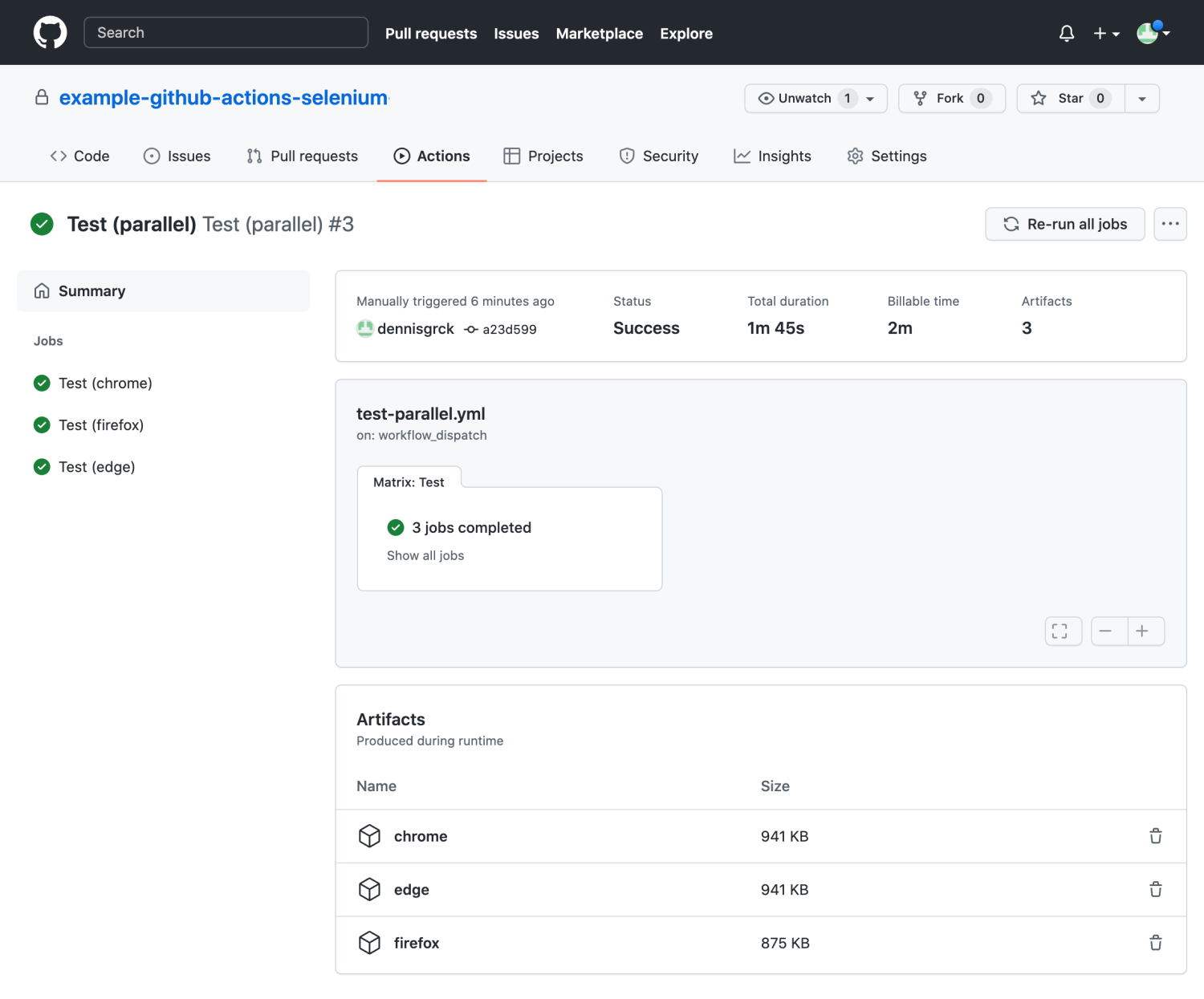
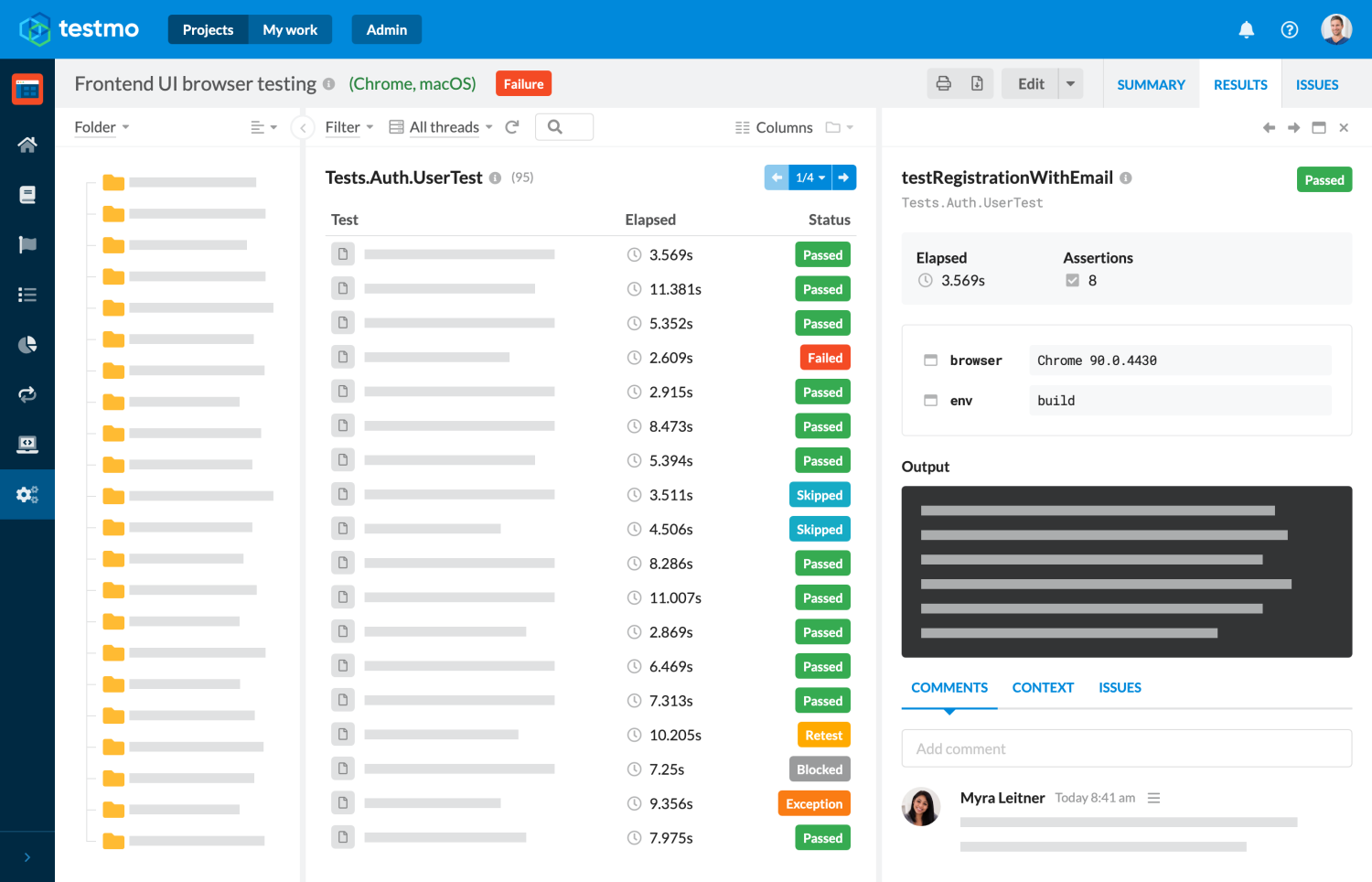
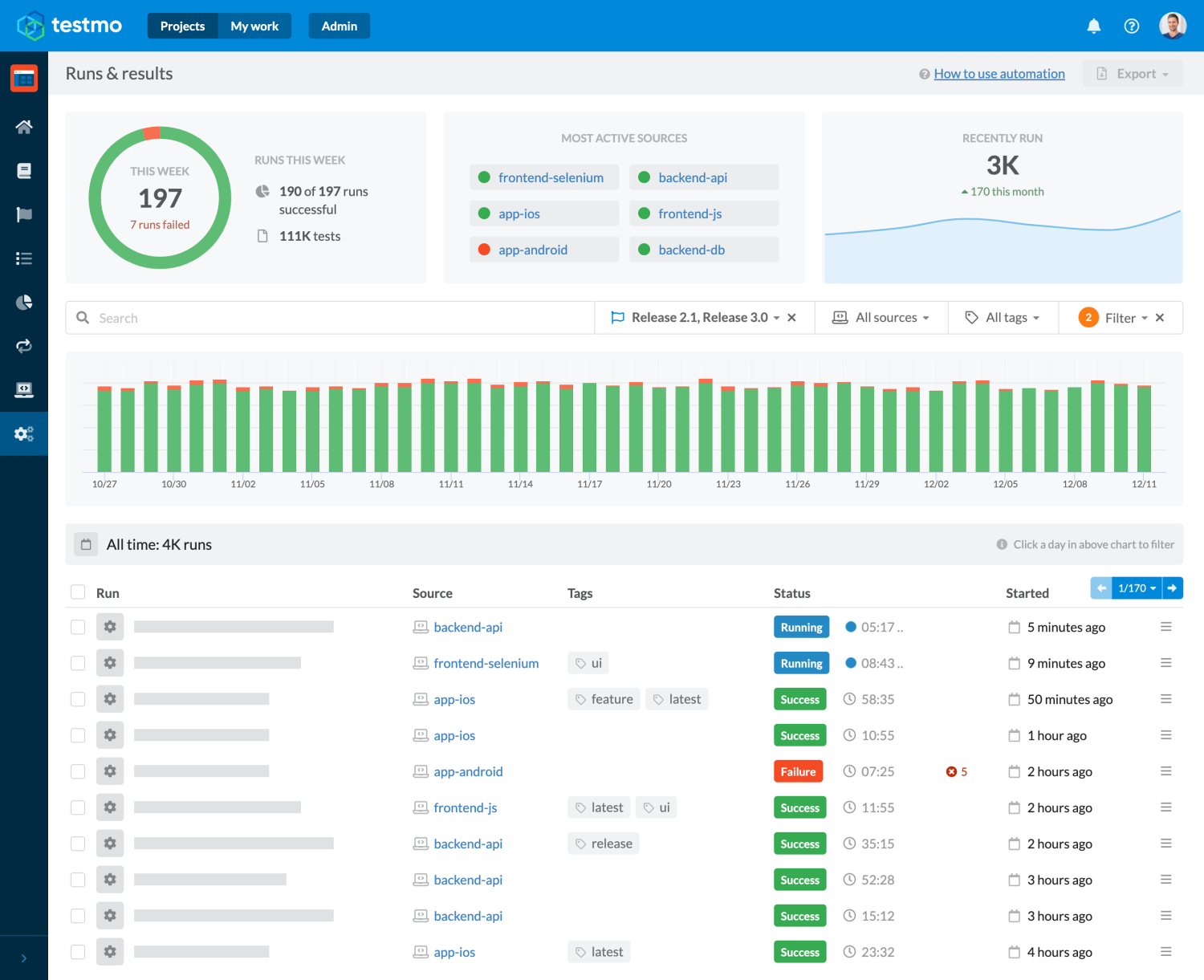
In this guide we will go through all the steps to set up Selenium browser test automation with GitHub Actions, including parallel testing against multiple browsers and reporting our results to test management.
GitHub Actions makes it very easy to run Selenium browser testing. If you are not yet familiar with basic test automation with GitHub Actions or how to run automated tests with Selenium, we have separate detailed guides on this. We recommend reading these articles if the concepts are completely new to you, as we will not cover the basics in this article:
- Selenium Test Automation & Reporting
- GitHub Actions Test Automation CI Pipeline
- GitHub Actions Parallel Test Automation Jobs
Once you are familiar with the basics of GitHub Actions test automation and Selenium browser automation, following this article will be very straightforward. So let's get started!